Over the past few months, my friends and I have gotten into the collectible trading card game Disney Lorcana. I decided that I wanted to use statistics to understand it better. I am not a competitive Lorcana player, so please take this article as the viewpoint of a motivated casual player.
Lorcana is a complex game, and complex games are difficult to model. Poker is a complex game as well, but I'm going to put it at the left end of the spectrum simply because we understand it pretty well at this point. Moving to the right we have deck-building games such as Dominion, and then even farther right are trading card games like Lorcana, which have a high number of unique cards with a variety of complex effects. Magic The Gathering has to occupy the right end of the spectrum, of course. It has an order of magnitude more cards than Lorcana, and it's even Turing Complete.
Despite the complexity, there are still some good resources that exist for modeling Lorcana in ways that are useful for competitive play. I really like this one from an actual high-level player.
But in general trading card games are not the place to look right now if you want to talk about counterfactual regret minimization or monte carlo tree search. The state-of-the-art will get there eventually, I'm sure, but it hasn't yet.
For now, I was curious if I could gain any insight into Lorcana by using linear regression to model individual cards. This is not especially useful for competitive play, but I thought it was an interesting exercise and that was enough for me to try it. I do think that it is moderately useful for non-competitive play, and as a learning tool for players new to the game.
If you just want the TL;DR for this post, here is the final linear model for predicting the Ink cost of Lorcana cards, a calculator to play with, and a lookup table for the predicted Ink cost of every Lorcana character card from sets 1 to 6:
Ink_Cost = -1.06704 +
0.47718 * Strength +
0.47718 * Willpower +
0.62207 * Lore +
0.39753 * Bodyguard +
# The relative amount that Shift reduces the Ink cost to play a card.
0.31899 * Shift +
# the relative amount that Singer is greater than the Ink cost to play a card.
0.21841 * Singer +
0.23768 * (Strength * Support) +
1.10404 * Evasive +
0.84077 * Rush +
0.31541 * Challenger +
0.71610 * Ward +
0.22977 * Reckless +
0.55122 * Resist
Ink Cost Calculator
Predicted Cost:
Card Lookup
Cost = Basic_Cost + Keyword_Cost + Bespoke_Cost + Residual
| Name | Strength | Willpower | Inkable | Lore | Keywords | Has_Bespoke | Is_Meta | Cost | Basic_Cost | Keyword_Cost | Bespoke_Cost | Residual |
|---|
I used a combination of Python for data scraping and R for analysis. I have published a repo here that contains all of the code and data needed to replicate or extend my analysis.
I also provide a CSV download here of the character card data that may be easier for others to use, and a list of cards that are commonly used in competitive decks here.
For this post, I'm not going to include any code. This is a stylistic choice because I want to write to a general audience. I will show the linear models, and some relevant data tables and statistical test outputs, but I aim to explain everything that I do in plain language.
Table of Contents#
Predicting card costs#
Card data#
My data source for Lorcana card information is lorcana-api.com via bulk download on 2025/02/19. I am grateful for them for providing this resource, but I do have to note that there were some data accuracy issues, especially with keywords and body text. I have not contacted them to fix these issues, so that's on me. I know how much work it is to put something like that together, and how unappreciated that work can be.
I fixed everything that I could find for keywords because it was important to my analysis, but there still may be some inaccuracies. If you notice any more data issues, then I would appreciate it if you raise an issue on the github repo so that I can correct them.
I will only be looking at character cards, and not actions, songs, items, or locations. I divide character cards into three groups by complexity: "basic" cards have no keywords or non-keyword abilities, "kwonly" cards have keywords but don't have non-keyword abilities, and "bespoke" cards have non-keyword abilities.
For basic and kwonly cards, I will be attempting to predict the Ink cost of the card based on the card attributes. Training models will give us insight into how much each attribute and keyword costs. Then, we will expect "good" cards to actually cost less than what the model predicts, and "bad" cards to actually cost more. For bespoke cards, I will only estimate the cost of their non-keyword abilities. It is too difficult to make an accurate model for bespoke cards.
Modeling basic cards#
I assume for the sake of my model that the Ink cost to play a card is a linear combination of its Strength (attack), Willpower (hitpoints), and Lore (victory points).
I think that this is a reasonable assumption. We know that the game designers have a vanilla curve for what stats a card can have based on its Ink cost. I think it is reasonable to assume that the vanilla curve can be approximated by a linear function.
I will use a single coefficient for the sum of Strength and Willpower, because they end up with almost identical coefficients even if I don't do that, and so I think that they probably do share a coefficient in reality.
I exclude Inkability (whether it can be played as a resource card), because it turns out that adding Inkability doesn't make the model more accurate, and the value of the Inkability coefficient is not stable when I remove one set at a time for cross-validation.
I have a bias towards building a model that is as simple as possible. A simple model protects me against over-fitting, which is a concern when there isn't much data.
As a final note, we are trying to use linear regression for causal inference. This is tricky, and not something that automatically works. Your level of confidence in the ability of this model to predict the ink cost of new Lorcana costs should reflect your level of confidence that I have included all important factors as inputs into the model.
Model:
Cost = -1.06704 + 0.47718 * StrengthPlusWillpower + 0.62207 * Lore
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.06704 0.08906 -11.98 <2e-16 ***
StrengthPlusWillpower 0.47718 0.01058 45.10 <2e-16 ***
Lore 0.62207 0.04535 13.72 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.419 on 164 degrees of freedom
Multiple R-squared: 0.9491, Adjusted R-squared: 0.9485
F-statistic: 1528 on 2 and 164 DF, p-value: < 2.2e-16
This very simple model is good enough to get us pretty high accuracy, and adding additional parameters doesn't really help. The model predicts 87% of basic cards to within half an Ink.
I chose half an Ink as my threshold for a successful prediction because in practice I would always round my prediction to the nearest Ink.
It is important to use the exact values for the coefficients. Rounding them to the nearest 0.1 drops the accuracy to 66%, and rounding them to the nearest 0.5 drops the accuracy to 50%. I want to say this explicitly because I know that people will do it otherwise if I don't warn them.
| Formula | Accuracy |
|---|---|
| -1.06704 + 0.47718 * StrengthPlusWillpower + 0.62207 * Lore | 0.8682635 |
| -1.07 + 0.48 * StrengthPlusWillpower + 0.62 * Lore | 0.8622754 |
| -1.1 + 0.5 * StrengthPlusWillpower + 0.6 * Lore | 0.6646707 |
| -1.0 + 0.5 * StrengthPlusWillpower + 0.5 * Lore | 0.502994 |
How do we gain confidence that the model isn't overfitted or fragile? We train the model six times, excluding one Set from training each time, and then test on the held out Set. If accuracy is maintained, and the coefficients don't change much, then we have evidence that we can trust our model. This process is called cross-validation.
| Held-out Set | Out-of-sample Accuracy | Formula |
|---|---|---|
| 1 | 0.875 | -0.9945993 + 0.4644756 * StrengthPlusWillpower + 0.6217872 * Lore |
| 2 | 0.9090909 | -1.1498291 + 0.4877223 * StrengthPlusWillpower + 0.6299706 * Lore |
| 3 | 0.9090909 | -1.0403014 + 0.4751897 * StrengthPlusWillpower + 0.6101202 * Lore |
| 4 | 0.88 | -1.0480664 + 0.4738874 * StrengthPlusWillpower + 0.6245760 * Lore |
| 5 | 0.6086957 | -1.1473403 + 0.4859783 * StrengthPlusWillpower + 0.6549590 * Lore |
| 6 | 0.8333333 | -1.0287587 + 0.4777975 * StrengthPlusWillpower + 0.5879933 * Lore |
This model works pretty well even when holding out one set, except for Set 5 (Shimmering Skies) for some reason, where the out-of-sample accuracy drops to 61%. I am not sure why that is, and it is certainly not ideal.
While we're doing cross-validation, I'll show you the problem with adding Inkability to the model. Adding it makes the out-of-sample accuracy noticeably worse, and the value of the Inkable parameter is not stable.
| Held-out Set | Out-of-sample Accuracy | Formula |
|---|---|---|
| 1 | 0.675 | -1.083815 + 0.4614744 * StrengthPlusWillpower + 0.12259284 * Inkable + 0.6332899 * Lore |
| 2 | 0.9090909 | -1.260223 + 0.4845139 * StrengthPlusWillpower + 0.14471860 * Inkable + 0.6446758 * Lore |
| 3 | 0.8181818 | -1.145395 + 0.4719321 * StrengthPlusWillpower + 0.13843427 * Inkable + 0.6232257 * Lore |
| 4 | 0.68 | -1.147758 + 0.4701966 * StrengthPlusWillpower + 0.14000404 * Inkable + 0.6360544 * Lore |
| 5 | 0.6086957 | -1.099656 + 0.4887699 * StrengthPlusWillpower - 0.07309825 * Inkable + 0.6499191 * Lore |
| 6 | 0.2083333 | -1.620512 + 0.4709926 * StrengthPlusWillpower + 0.56866354 * Inkable + 0.6568603 * Lore |
And for completeness, here is the model with separate Strength and Willpower. As you can see, combining the terms makes sense:
Model:
Cost = -1.06870 + 0.46912 * Strength + 0.48427 * Willpower + 0.62117 * Lore
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -1.06870 0.08937 -11.96 <2e-16 ***
Strength 0.46912 0.02177 21.55 <2e-16 ***
Willpower 0.48427 0.01982 24.44 <2e-16 ***
Lore 0.62117 0.04551 13.65 <2e-16 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.42 on 163 degrees of freedom
Multiple R-squared: 0.9491, Adjusted R-squared: 0.9482
F-statistic: 1014 on 3 and 163 DF, p-value: < 2.2e-16
Note that it is still possible for one of Strength or Willpower to actually be more useful than the other. All we have learned is that the game values them identically when determining the Ink cost of a card.
So now we have our model, and we know that it is probably about right to say that a point of Strength or Willpower costs 0.48 Ink, and a point of Lore costs 0.62 Ink. What can we do with that?
"Residuals" in statistics are the differences between the dependent variable and what the model predicts that it should be. The process of least-squares regression, which is what we have just done, minimizes the sum of the squared residuals.
If we assume that the model is accurate, then cards with a negative residual should be "good", and cards with a positive residual should be "bad". What do the residuals look like for this model?
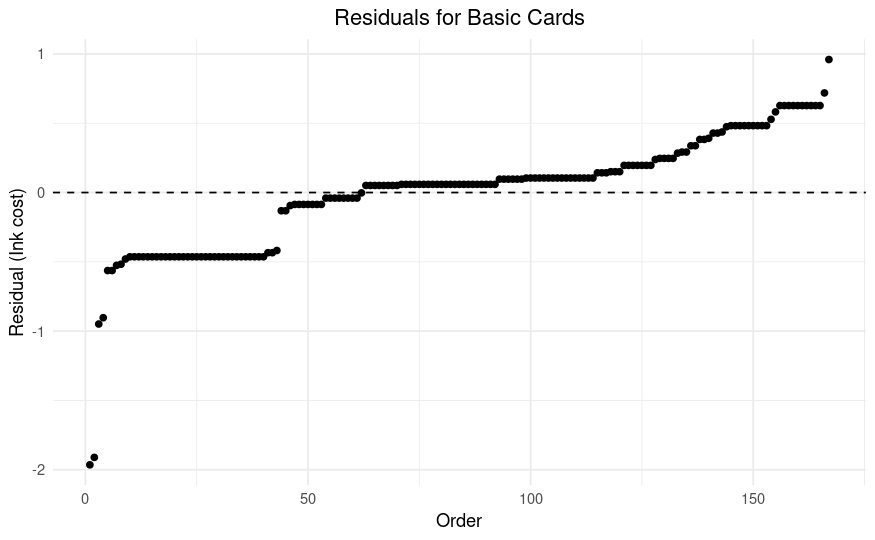
I think that the main takeaway from this plot is that there are a lot of cards with residuals around -0.5, and those cards are plausibly better than the other basic cards. That also might explain why slightly changing the coefficients of the linear model reduces the accuracy so much, and why holding out Set 5 led to a drop in accuracy. Those cards are so close to -0.5 that putting them on the wrong side of it would tank the accuracy of the model.
Now, let's look at the best and worse basic cards.
These are the cards that the model considers to be the most underpriced:
| Name | Cost | Strength | Willpower | Inkable | Lore | Residual |
|---|---|---|---|---|---|---|
| Goofy - Knight for a Day | 9 | 10 | 10 | Yes | 4 | -1.9648087 |
| Sir Ector - Castle Lord | 7 | 7 | 10 | No | 3 | -1.9112037 |
| Scrooge McDuck - Afficionado of Antiquities | 4 | 5 | 5 | No | 2 | -0.9488827 |
| Denahi - Avenging Brother | 5 | 7 | 5 | No | 2 | -0.9032407 |
The first two cards are both very powerful cards with high Strength and high Willpower, so they are not normal cards and it is unsurprising that the model doesn't predict them well.
There is an argument that Cost should be proportional to the log of Strength and the log of Willpower, because each incremental Strength and Willpower point is worth less (because it's less likely to ever matter during a game). Then, the marginal Strength and Willpower for these cards would be worth less, and we would predict them better.
I don't think it's worth adding that complexity here. It makes it harder to understand the model intuitively, and it only matters for a few cards like these. I want a simple, intuitive model for my purposes.
The second two cards I think are just strong cards. They are not Inkable, which provides some balance.
These are the cards that the model considers to be the most overpriced:
| Name | Cost | Strength | Willpower | Inkable | Lore | Residual |
|---|---|---|---|---|---|---|
| Pete - Rotten Guy | 4 | 1 | 5 | Yes | 2 | 0.9598332 |
| Sven - Official Ice Deliverer | 6 | 5 | 7 | Yes | 1 | 0.7188273 |
I think that these cards are just weak. Compare "Pete - Rotten Guy" to "Scrooge McDuck - Afficionado of Antiquities". Scrooge has 4 more strength and only gives up being Inkable. "Nala - Fierce Friend" and "Piglet - Very Small Animal" are both identical to "Pete - Rotten Guy" except for moving points between Strength and Willpower, and they are both Cost 3:
| Name | Cost | Strength | Willpower | Inkable | Lore | Residual |
|---|---|---|---|---|---|---|
| Nala - Fierce Friend | 3 | 2 | 4 | Yes | 2 | -0.04016676 |
| Piglet - Very Small Animal | 3 | 2 | 4 | Yes | 2 | -0.04016676 |
Modeling kwonly cards#
We want to layer this on top of the model for basic cards. What I'm going to do is first calculate a predicted Basic_Cost for each of the kwonly cards, and then subtract that Basic_Cost from the Cost to get the Keyword_Cost. Our new model will predict the Keyword_Cost and then add parameters for each of the keyword abilities.
Some of the keywords take a numeric argument, and that numeric argument is not always exactly the number that is on the card.
For Bodyguard, Challenger, and Resist, the numeric argument is the number that is on the card. This makes an assumption that e.g. Challenger +2 is exactly twice as good as Challenger +1. This is probably not completely accurate but it should be right level of detail for us.
For Shift and Singer, the numeric argument is based on the difference between the number that is on the card and the Ink cost. Shift and Singer replace the Ink cost in certain situations, so they modify the Ink cost, and a 6 Ink cost card with Shift 4 has a Shift argument of 2 in my model.
For Support, the numeric argument is equal to the Strength of the card, because Support adds the card's Strength to another card when it quests.
The other keywords--Evasive, Rush, Ward, and Reckless--do not have a numeric argument, so they are binary yes/no parameters.
Note that we are again trying to use linear regression for causal inference. It is trickier to account for all factors with a more complex model, so your level of confidence in the ability of this model to predict the ink cost of new Lorcana costs should be lower than for the basic model.
Model:
Keyword_Cost = 0 +
0.39753 * Bodyguard +
0.31899 * Shift +
0.21841 * Singer +
0.23768 * Support +
1.10404 * Evasive +
0.84077 * Rush +
0.31541 * Challenger +
0.71610 * Ward +
0.22977 * Reckless +
0.55122 * Resist
Coefficients:
Estimate Std. Error t value Pr(>|t|)
Bodyguard 0.39753 0.10082 3.943 0.000152 ***
Shift 0.31899 0.09326 3.420 0.000916 ***
Singer 0.21841 0.06313 3.459 0.000806 ***
Support 0.23768 0.03245 7.325 7.08e-11 ***
Evasive 1.10404 0.07312 15.098 < 2e-16 ***
Rush 0.84077 0.09275 9.065 1.40e-14 ***
Challenger 0.31541 0.05182 6.087 2.30e-08 ***
Ward 0.71610 0.10762 6.654 1.70e-09 ***
Reckless 0.22977 0.13030 1.763 0.080992 .
Resist 0.55122 0.15183 3.631 0.000454 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3627 on 97 degrees of freedom
Multiple R-squared: 0.8646, Adjusted R-squared: 0.8507
F-statistic: 61.96 on 10 and 97 DF, p-value: < 2.2e-16
Why is Reckless positive despite clearly being a debuff? I think that Reckless cards are priced under the assumption that they have a single Lore that they can't use. If we assume that Reckless cards implicitly have 1 Lore, then the new coefficient for Reckless is the old coefficient for Reckless minus the coefficient for Lore, which gives us 0.22977 - 0.62207 = -0.3923, which I think is a fair estimate for the cost of Reckless. I don't think I agree with the way that Reckless cards are priced.
I don't have much to say about the other keywords except that the coefficients look right to me.
I will say that I also tried treating Inkability as a keyword, to see if its coefficient would be significantly non-zero. This would be justified if it were the case that Inkability mattered more for kwonly cards than for basic cards, such that Inkability was noise for basic cards but was useful signal for kwonly cards. This is a plausible theory, so let's see:
Model:
Keyword_Cost = 0 +
0.02487 * Inkable +
0.39753 * Bodyguard +
0.31899 * Shift +
0.21841 * Singer +
0.23768 * Support +
1.10404 * Evasive +
0.84077 * Rush +
0.31541 * Challenger +
0.71610 * Ward +
0.22977 * Reckless +
0.55122 * Resist
Coefficients:
Estimate Std. Error t value Pr(>|t|)
Inkable 0.02487 0.08327 0.299 0.765841
Bodyguard 0.37801 0.12054 3.136 0.002274 **
Shift 0.32207 0.09427 3.417 0.000931 ***
Singer 0.20710 0.07387 2.804 0.006113 **
Support 0.23073 0.04005 5.761 1.01e-07 ***
Evasive 1.08370 0.10018 10.818 < 2e-16 ***
Rush 0.83970 0.09326 9.004 2.05e-14 ***
Challenger 0.30911 0.05616 5.504 3.09e-07 ***
Ward 0.69634 0.12676 5.493 3.23e-07 ***
Reckless 0.22071 0.13439 1.642 0.103780
Resist 0.53700 0.15980 3.360 0.001118 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3644 on 96 degrees of freedom
Multiple R-squared: 0.8648, Adjusted R-squared: 0.8493
F-statistic: 55.81 on 11 and 96 DF, p-value: < 2.2e-16
The Inkable parameter has a coefficient of 0.02, and that coefficient is not significantly-nonzero. So we will not include Inkability in our kwonly model.
While we're at it, notice that my kwonly model forces an Intercept coefficient of 0. This makes sense because a card with zero keywords should have zero Keyword_Cost, because it is actually a basic card. If we added an Intercept coefficient, would it be significantly-nonzero? We hope that it will not be:
Model:
Keyword_Cost = 0.10741 +
0.30946 * Bodyguard +
0.32745 * Shift +
0.16958 * Singer +
0.20479 * Support +
1.00360 * Evasive +
0.75717 * Rush +
0.27961 * Challenger +
0.61480 * Ward +
0.14326 * Reckless +
0.47317 * Resist
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.10741 0.11369 0.945 0.347187
Bodyguard 0.30946 0.13735 2.253 0.026534 *
Shift 0.32745 0.09374 3.493 0.000724 ***
Singer 0.16958 0.08161 2.078 0.040390 *
Support 0.20479 0.04760 4.302 4.07e-05 ***
Evasive 1.00360 0.12906 7.776 8.44e-12 ***
Rush 0.75717 0.12824 5.905 5.34e-08 ***
Challenger 0.27961 0.06422 4.354 3.34e-05 ***
Ward 0.61480 0.15196 4.046 0.000106 ***
Reckless 0.14326 0.15932 0.899 0.370784
Resist 0.47317 0.17292 2.736 0.007403 **
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3629 on 96 degrees of freedom
Multiple R-squared: 0.5383, Adjusted R-squared: 0.4902
F-statistic: 11.19 on 10 and 96 DF, p-value: 1.889e-12
The Intercept term has a coefficient of 0.11, and it is not significantly-nonzero, which is what we had hoped for.
Back to the original kwonly model. Again, we'll look at the residuals:
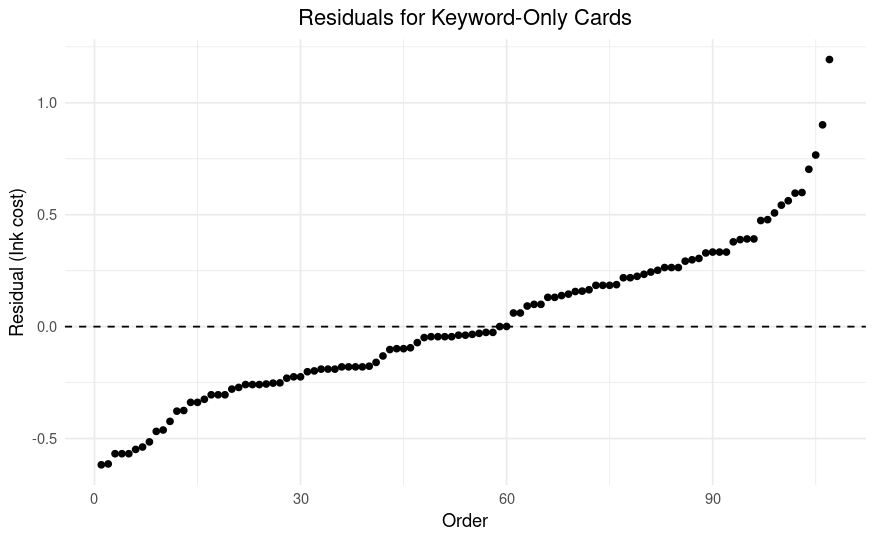
Thankfully, the error rate is still pretty good, at 84%. We should however be intuitively less confident in the exact values of these parameters because we are training a more complex model on proportionally less data, and because it is more likely that we are missing factors, because the keyword effects are complex.
| Held-out Set | Out-of-sample Accuracy |
|---|---|
| 1 | 0.7619048 |
| 2 | 0.9444444 |
| 3 | 0.8 |
| 4 | 0.8235294 |
| 5 | 0.8125 |
| 6 | 0.9333333 |
| Keyword | Min value over all held-out sets | Max value over all held-out sets |
|---|---|---|
| Bodyguard | 0.3231928 | 0.4389048 |
| Shift | 0.2347090 | 0.3682603 |
| Singer | 0.2104870 | 0.2406689 |
| Support | 0.2008330 | 0.2661130 |
| Evasive | 0.9838881 | 1.1575138 |
| Rush | 0.7482291 | 0.8809805 |
| Challenger | 0.2790733 | 0.3461545 |
| Ward | 0.6659889 | 0.7480462 |
| Reckless | 0.1444510 | 0.3086036 |
| Resist | 0.4337512 | 0.6885117 |
Cross-validation also confirms that the kwonly model works well enough.
These are the cards that the model considers to be the most underpriced:
| Name | Cost | Strength | Willpower | Inkable | Lore | Keywords | Residual |
|---|---|---|---|---|---|---|---|
| Captain Hook - Forceful Duelist | 1 | 1 | 2 | Yes | 1 | Challenger 2 | -0.6173778 |
| Pegasus - Gift for Hercules | 1 | 1 | 1 | Yes | 1 | Evasive | -0.6134227 |
Yeah, these ones just seem generally good. An evasive 1-drop can immediately start racking up lore and probably can't be countered for a few turns. And the Challenger 2 is already on top of a good card.
These are the cards that the model considers to be the most overpriced:
| Name | Cost | Strength | Willpower | Inkable | Lore | Keywords | Residual |
|---|---|---|---|---|---|---|---|
| Chief Tui - Respected Leader | 7 | 3 | 6 | Yes | 3 | Support | 1.1931914 |
| Tigger - Wonderful Thing | 6 | 4 | 4 | Yes | 2 | Evasive | 0.9014353 |
For both of these, it seems like you're just overpaying for the ability that you get. I think that these are just generally bad cards.
This is reassuring. We had some obvious outliers on the basic cards, although to be fair they were very weird basic cards, but the most extreme kwonly cards all seem reasonable.
Not modeling bespoke cards#
Now we move onto cards with bespoke abilities.
Note that we're doing something different here from what we have been doing. For basic and kwonly cards, we designed the formula for a model, trained a linear model using that formula, validated that the model was reasonable, predicted a cost for each card using that model, and evaluated whether the card was "good" by the value of the residual. Negative residuals were good, because it meant that the actual cost of the card was below what we predicted it would be, which meant that the card was undervalued according to our model. Positive residuals were bad, because it meant that the card was overvalued according to our model.
Here, we are not training a model, because I do not have a design for what the formula would look like, because there are many different bespoke abilities that combine effects in various ways, and the whole thing seems very complicated.
Instead, we are predicting the cost of the card as if it were a kwonly card, taking that value to be the true cost of the bespoke card if it didn't have any bespoke abilities, and then saying that the value of the bespoke abilities is the actual cost of the card minus the predicted cost of the card as a kwonly card.
So for this part a positive Bespoke_Cost means that the bespoke abilities are beneficial, and make a card cost more, and a negative Bespoke_Cost means that the bespoke abilities are detrimental, and make a card cost less.
The Bespoke_Cost has error bars that are at least as wide as the error bars from the kwonly model. So we should expect the Bespoke_Costs to be +/- 0.5 or even more than that.
We can't really do anything else without a model, but I think that just looking at the bespoke costs of various abilities is enough to find some interesting stuff.
These are the cards whose bespoke abilities the model considers to be the most beneficial:
| Name | Bespoke Cost | Bespoke Abilities |
|---|---|---|
| Kristoff - Reindeer Keeper | 4.275658 | Song of the Herd - For each song card in your discard, you pay 1 Ink less to play this character. |
| Mickey Mouse - Trumpeter | 3.967796 | Sound The Call - {e}, 2{i}: Play a character for free. |
| Magic Broom - Dancing Duster | 3.581901 | Power Clean - When you play this character, if you have a Sorcerer character in play, you may exert chosen opposing character. They can't ready at the start of their next turn. |
| Lady Tremaine - Wicked Stepmother | 3.581901 | Do It Again! - When you play this character, you may return an action card from your discard to your hand. |
| Maleficent - Monstrous Dragon | 3.096759 | Dragon Fire - When you play this character, you may banish chosen character. |
| Lucifer - Cunning Cat | 2.914191 | Mouse Catcher: When you play this character, each opponent chooses and discards either 2 cards or 1 action card. |
| Peter Pan - Never Land Prankster | 2.673185 | Look Innocent - This character enters play exerted. Can't Take a Joke? - While this character is exerted, each opposing player can't gain lore unless one of their characters has challenged this turn. |
| Magica De Spell - The Midas Touch | 2.657271 | All Mine - Whenever this character quests, gain lore equal to the cost of one of your items in play. |
| Madame Medusa - The Boss | 2.627543 | That Terrible Woman - When you play this character, banish chosen opposing character with 3{s} or less. |
| Pepa Madrigal - Weather Maker | 2.581901 | It Looks Like Rain - When you play this character, you may exert chosen opposing character. That character can't ready at the start of their next turn unless they're at a location. |
These are the cards whose bespoke abilities the model considers to be the most detrimental:
| Name | Bespoke Cost | Bespoke Abilities |
|---|---|---|
| Gustav the Giant - Terror of the Kingdom | -2.281173 | All Tied Up - This character enters play exerted and can't ready at the start of your turn. Break Free - During your turn, whenever one of your other characters banishes another character in a challenge, you may ready this character. |
| Treasure Guardian - Protector of the Cave | -1.903241 | Who Disturbs My Slumber? - This character can't challenge or quest unless it is at a location. |
| Mirabel Madrigal - Family Gatherer | -1.815087 | Not Without My Family - You can't play this character unless you have 5 or more characters in play. |
| Daisy Duck - Donald's Date | -1.562988 | Big Prize - Whenever this character quests, each opponent reveals the top card of their deck. If it's a character card, they may put it into their hand. Otherwise, they put it on the bottom of their deck. |
| Golden Harp - Enchanter of the Land | -1.562988 | Stolen Away - At the end of your turn, if you didn't play a song this turn, banish this character. |
| Flynn Rider - His Own Biggest Fan | -1.549146 | One Last, Big Score - This character gets -1 Lore for each card in your opponents' hands. |
| Megara - Captivating Cynic | -1.471704 | Shady Deal - When you play this character, choose and discard a card or banish this character. |
| Madam Mim - Purple Dragon | -1.251417 | I win, I win! - When you play this character, banish her or return another 2 chosen characters of yours to your hand. |
| Mr. Smee - Bumbling Mate | -1.040167 | Oh Dear, Dear, Dear - At the end of your turn, if this character is exerted and you don't have a Captain character in play, deal 1 damage to this character. |
| Beast - Wounded | -0.994525 | That Hurts!: This character enters play with 4 damage. |
I think that it's probably reasonable to assume +/- 0.5 ink error bars on the values of these abilities, given that that's mostly what we saw on the other categories of cards. But that's based on nothing and +/- 1 ink error bars would certainly be safer.
Dragon Fire costs 3.10 as a bespoke ability, but 5 as an action card, so you get a hefty discount for combining the character and the action. Of course, "Maleficient - Monstrous Dragon" is a 9-drop card, so you can only use the ability in the endgame, and the character is not a full replacement for the separate action card.
If we assume that the two Dragon Fires are well-balanced, then we have learned that the game values a 5 Ink action card at 3 Ink when paired with a 6-drop card. That is interesting insight that it would have been difficult to find out any other way.
| Name | Bespoke Cost | Bespoke Abilities |
|---|---|---|
| Magic Broom - Dancing Duster | 3.581901 | Power Clean - When you play this character, if you have a Sorcerer character in play, you may exert chosen opposing character. They can't ready at the start of their next turn. |
| Elsa - Spirit of Winter | 1.791067 | Deep Freeze - When you play this character, exert up to 2 chosen characters. They can't ready at the start of their next turn. |
"Elsa - Spirit of Winter" can exert two characters and keep them from readying at the start of their next turn for a bespoke cost of 1.79 ink, whereas "Magic Broom - Dancing Duster" does something strictly worse (one character, with a condition) for a bespoke cost of 3.58.
This makes Elsa's ability roughly four times as valuable as Magic Broom's. Both of these are Amethyst cards, why are the abilities valued so differently? Part of the answer is surely that Elsa is an 8-drop card, and abilities seem to be cheaper when paired with high cost cards, but surely that doesn't explain everything. There's a reason that Elsa is expensive in dollars and Magic Broom is cheap in dollars, after all.
I am sure that there are other interesting observations that can be made, but I will leave them to readers to find.
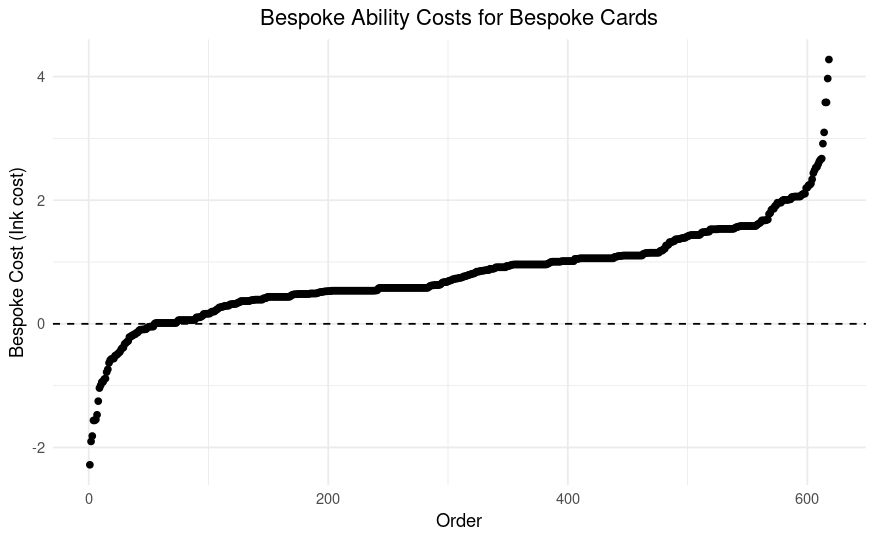
Remember, this plot shows the costs of bespoke abilities, not residuals. What we learn from this plot is that most bespoke abilities are positive, and the most extreme positive abilities are more extreme than the most extreme negative abilities.
Analyzing meta-relevant cards#
Another way to evaluate whether our models are useful is to see if they predict whether a card is used in meta decks at competitive tournaments. We want to know if the residuals for cards used in meta decks are drawn from a different distribution from the residuals for card not used in meta decks. "Drawn from a different distribution" is a technical way of saying that two populations are "different" in statistics.
At the same time, we'll check whether Inkability affects if a card gets chosen for meta decks, by seeing whether the proportion of Inkable meta-relevant cards is different from the proportion of Inkable non-meta-relevant cards.
Both of these questions are best answered by statistical tests. For checking whether the residuals are drawn from different distributions, we will use the Kruskal-Wallis rank sum test, which is convenient for us because it does not make many assumptions about the form of our data (unlike ANOVA). For checking whether the Inkability proportions are different, we will use the Fisher's exact test.
The important thing to know about these tests is that they will give us back a p-value, which is the probability of seeing this result (or a more extreme result) assuming that the distributions, or proportions, are in fact the same, which is the null hypothesis. We will reject the null hypothesis if the p-value fall below 0.05, as is customary.
Meta deck data#
Here is a CSV file for the list of meta-relevant cards and the meta archetypes that use them. This CSV includes all cards, not just character cards.
I looked at every "Tier 1" and "Tier 2" meta archetype on inkdecks on 2025/02/19, which is every archetype with at least a 5% metashare, and cumulatively 83% metashare. Then, I picked every card listed as a "Key Card", as well as any card that was present in at least 20% of decks within the archetype. I consider this the set of "meta-relevant" cards.
Meta basic cards#
This is the full list of meta-relevant basic cards:
| Name | Cost | Strength | Willpower | Inkable | Lore | Residual |
|---|---|---|---|---|---|---|
| Gantu - Captain Crankyhead | 5 | 4 | 3 | No | 4 | 0.2385182 |
| Maleficent - Biding Her Time | 1 | 1 | 1 | No | 2 | -0.1314508 |
| Robin Hood - Beloved Outlaw | 1 | 2 | 2 | Yes | 1 | -0.4637408 |
| The Queen - Regal Monarch | 1 | 2 | 2 | Yes | 1 | -0.4637408 |
| Olaf - Friendly Snowman | 1 | 1 | 3 | Yes | 1 | -0.4637408 |
| Minnie Mouse - Always Classy | 1 | 1 | 3 | Yes | 1 | -0.4637408 |
| Banzai - Gluttonous Predator | 2 | 3 | 2 | No | 2 | -0.5629878 |
Kruskal-Wallis rank sum test
data: Basic Meta residuals, Basic Non-Meta residuals
Kruskal-Wallis chi-squared = 6.1908, df = 1, p-value = 0.01284
Basic Meta Mean: -0.3301262
Basic Non-Meta Mean: 0.01444302
Yes, the residuals from the basic meta cards are drawn from a distribution with a different mean from the residuals from the basic non-meta cards, at a significant level.
This gives us some confidence that the basic model is useful for finding genuinely good cards.
This is the contingency table for the Fisher's exact test:
| Is Meta? | Non-Inkable | Inkable |
|---|---|---|
| Yes | 3 | 4 |
| No | 31 | 129 |
Fisher's Exact Test for Count Data
data: Basic cards contingency table
p-value = 0.1501
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.4311601 19.3221385
sample estimates:
odds ratio
3.093437
Inconclusive. If anything, non-Inkable cards are more likely to be picked.
Meta kwonly cards#
This is the full list of meta-relevant kwonly cards:
| Name | Cost | Strength | Willpower | Inkable | Lore | Keywords | Residual |
|---|---|---|---|---|---|---|---|
| Minnie Mouse - Stylish Surfer | 3 | 1 | 3 | Yes | 2 | Evasive, | -0.1898487 |
| Chien-Po - Imperial Soldier | 5 | 4 | 7 | Yes | 1 | Bodyguard, | -0.2015211 |
| HeiHei - Boat Snack | 1 | 1 | 2 | Yes | 1 | Support, | -0.2242407 |
| Maui - Hero to All | 5 | 6 | 5 | Yes | 0 | Rush, Reckless, | -0.2524709 |
| Queen Of Hearts - Impulsive Ruler | 2 | 2 | 2 | Yes | 1 | Rush, | -0.3045157 |
| Ursula - Vanessa | 2 | 1 | 4 | Yes | 1 | Singer4, | -0.3777319 |
| Cinderella - Ballroom Sensation | 1 | 1 | 2 | Yes | 1 | Singer3, | -0.4233739 |
| Sir Hiss - Aggravating Asp | 2 | 3 | 1 | Yes | 1 | Evasive, | -0.5677807 |
| Pegasus - Gift for Hercules | 1 | 1 | 1 | Yes | 1 | Evasive, | -0.6134227 |
I also want to take the time to note that there is only one Reckless meta-relevant card:
| Name | Cost | Strength | Willpower | Inkable | Lore | Keywords | Residual |
|---|---|---|---|---|---|---|---|
| Maui - Hero to All | 5 | 6 | 5 | Yes | 0 | Rush, Reckless, | -0.2524709 |
Why is "Maui - Hero to All" used? It's the highest strength Inkable Rush card available to Ruby. If we gave Reckless the coefficient that I feel it should have then it would have a slightly positive residual of 0.37, which still isn't terrible.
| Name | Cost | Strength | Willpower | Inkable | Lore | Keywords |
|---|---|---|---|---|---|---|
| Kakamora - Boarding Party | 4 | 5 | 2 | No | 1 | Rush, |
| Goofy - Flying Goof | 6 | 5 | 5 | No | 1 | Evasive, Rush, |
| Maui - Hero to All | 5 | 6 | 5 | Yes | 0 | Rush, Reckless, |
| Hercules - Daring Demigod | 5 | 7 | 3 | No | 0 | Rush, Reckless, |
If we look at the other Reckless cards, we find that all of them are positive residuals if we consider the true cost of Reckless, except for one other card:
| Name | Cost | Strength | Willpower | Inkable | Lore | Keywords | Residual |
|---|---|---|---|---|---|---|---|
| Tuk Tuk - Wrecking Ball | 4 | 4 | 5 | No | 0 | Reckless, | 0.54266212 |
| Hercules - Daring Demigod | 5 | 7 | 3 | No | 0 | Rush, Reckless, | 0.22470815 |
| Te Ka - The Burning One | 6 | 8 | 6 | No | 0 | Reckless, | 0.15676714 |
| Della Duck - Unstoppable Mom | 2 | 3 | 3 | No | 0 | Reckless, | -0.02580089 |
| Gaston - Arrogant Hunter | 2 | 4 | 2 | Yes | 0 | Reckless, | -0.02580089 |
| Felicia - Always Hungry | 1 | 3 | 1 | Yes | 0 | Reckless, | -0.07144290 |
| Maui - Hero to All | 5 | 6 | 5 | Yes | 0 | Rush, Reckless, | -0.25247085 |
| Arthur - Novice Sparrow | 1 | 2 | 3 | No | 0 | Reckless, | -0.54862189 |
"Arthur - Novice Sparrow" seems like it could also be a solid choice. It isn't Inkable, though.
Kruskal-Wallis rank sum test
data: kwonly Meta Residuals, kwonly Non-Meta Residuals
Kruskal-Wallis chi-squared = 12.822, df = 1, p-value = 0.0003425
kwonly Meta Mean: -0.3505451
kwonly Non-Meta Mean: 0.04335732
Yes, the residuals from the kwonly meta cards are drawn from a distribution with a different mean from the residuals from the kwonly non-meta cards, at a significant level.
This gives us some confidence that the kwonly model is useful for finding genuinely good cards.
This is the contingency table for the Fisher's exact test:
| Is Meta? | Non-Inkable | Inkable |
|---|---|---|
| Yes | 0 | 9 |
| No | 27 | 71 |
Fisher's Exact Test for Count Data
data: Keyword-only contingency table
p-value = 0.1079
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.000000 1.446478
sample estimates:
odds ratio
0
Inconclusive, but Inkable cards are more likely to be picked.
Meta bespoke cards#
This is the full list of meta-relevant bespoke cards:
| Name | Cost | Strength | Willpower | Inkable | Lore | Keywords | Bespoke Cost |
|---|---|---|---|---|---|---|---|
| Madame Medusa - The Boss | 6 | 4 | 4 | No | 1 | 2.62754326 | |
| Hades - Infernal Schemer | 7 | 3 | 6 | No | 2 | 2.52829625 | |
| Sisu - Empowered Sibling | 8 | 5 | 4 | No | 3 | Shift 6, | 2.26824555 |
| Tamatoa - So Shiny! | 8 | 5 | 8 | Yes | 1 | 2.24164828 | |
| Merlin - Rabbit | 4 | 2 | 3 | No | 1 | 2.05908025 | |
| Lady Tremaine - Imperious Queen | 6 | 3 | 4 | No | 2 | Shift 4, | 1.84467156 |
| Elsa - Spirit of Winter | 8 | 4 | 6 | No | 3 | Shift 6, | 1.79106655 |
| Hades - King of Olympus | 8 | 6 | 7 | No | 1 | Shift 6, | 1.60366559 |
| Gramma Tala - Keeper of Ancient Stories | 4 | 3 | 3 | Yes | 1 | 1.58190125 | |
| Belle - Strange but special | 4 | 2 | 4 | Yes | 1 | 1.58190125 | |
| Kit Cloudkicker - Tough Guy | 3 | 2 | 2 | Yes | 1 | 1.53625924 | |
| Maleficent - Sorceress | 3 | 2 | 2 | Yes | 1 | 1.53625924 | |
| Pinocchio - Talkative Puppet | 2 | 1 | 1 | No | 1 | 1.49061724 | |
| Donald Duck - Focused Flatfoot | 5 | 3 | 4 | Yes | 2 | 1.48265424 | |
| Sisu - Daring Visitor | 3 | 1 | 1 | No | 1 | Evasive, | 1.38657730 |
| Yzma - Scary Beyond All Reason | 6 | 4 | 4 | Yes | 2 | Shift 4, | 1.36749256 |
| Pluto - Guard Dog | 4 | 1 | 5 | No | 1 | Bodyguard, | 1.18437386 |
| Ariel - Treasure Collector | 6 | 3 | 4 | No | 3 | Ward, | 1.14448689 |
| Merlin - Goat | 4 | 4 | 3 | Yes | 1 | 1.10472225 | |
| Hiram Flaversham - Toymaker | 4 | 1 | 6 | Yes | 1 | 1.10472225 | |
| Ursula - Deceiver of All | 3 | 2 | 3 | Yes | 1 | 1.05908025 | |
| Morph - Space Goo | 2 | 2 | 1 | Yes | 1 | 1.01343824 | |
| Kuzco - Wanted Llama | 2 | 1 | 2 | Yes | 1 | 1.01343824 | |
| Tipo - Growing Son | 2 | 1 | 2 | Yes | 1 | 1.01343824 | |
| Beast - Hardheaded | 5 | 4 | 4 | Yes | 2 | 1.00547524 | |
| Diablo - Obedient Raven | 1 | 0 | 1 | No | 1 | 0.96779623 | |
| Friar Tuck - Priest of Nottingham | 4 | 2 | 4 | Yes | 2 | 0.95983324 | |
| Sven - Reindeer Steed | 4 | 3 | 3 | Yes | 2 | 0.95983324 | |
| Clarabelle - Light on Her Hooves | 7 | 5 | 6 | Yes | 2 | Shift 5, | 0.93595557 |
| Lawrence - Jealous Manservant | 3 | 0 | 4 | Yes | 2 | 0.91419123 | |
| Tinker Bell - Giant Fairy | 6 | 4 | 5 | Yes | 2 | Shift 4, | 0.89031356 |
| The Muses - Proclaimers of Heroes | 4 | 2 | 4 | Yes | 1 | Ward, | 0.86580192 |
| Goofy - Musketeer | 5 | 3 | 6 | Yes | 1 | Bodyguard, | 0.75283687 |
| Gaston - Intellectual Powerhouse | 6 | 4 | 4 | No | 3 | Shift 4, | 0.74542455 |
| Scar - Vicious Cheater | 7 | 6 | 5 | No | 2 | Rush, | 0.73316327 |
| Prince John - Greediest of All | 3 | 1 | 2 | No | 2 | Ward, | 0.67527089 |
| Ariel - Spectacular Singer | 3 | 2 | 3 | Yes | 1 | Singer5, | 0.62226809 |
| The White Rose - Jewel of the Garden | 3 | 3 | 3 | No | 1 | 0.58190125 | |
| John Silver - Ship's Cook | 3 | 3 | 3 | No | 1 | 0.58190125 | |
| Lyle Tiberius Rourke - Cunning Mercenary | 3 | 2 | 4 | No | 1 | 0.58190125 | |
| Merlin - Crab | 3 | 3 | 3 | Yes | 1 | 0.58190125 | |
| Pete - Games Referee | 3 | 3 | 3 | Yes | 1 | 0.58190125 | |
| Piglet - Pooh Pirate Captain | 2 | 2 | 2 | Yes | 1 | 0.53625924 | |
| Ursula - Deceiver | 2 | 1 | 3 | Yes | 1 | 0.53625924 | |
| Doc - Bold Knight | 2 | 1 | 3 | No | 1 | 0.53625924 | |
| Flynn Rider - Frenemy | 2 | 2 | 2 | Yes | 1 | 0.53625924 | |
| The Queen - Commanding Presence | 5 | 4 | 3 | Yes | 2 | Shift 2, | 0.52568021 |
| Prince Naveen - Ukulele Player | 4 | 3 | 3 | Yes | 2 | Singer6, | 0.52302108 |
| Judy Hopps - Optimistic Officer | 3 | 2 | 3 | Yes | 2 | 0.43701223 | |
| Benja - Guardian of the Dragon Gem | 3 | 2 | 3 | Yes | 2 | 0.43701223 | |
| Anna - Diplomatic Queen | 3 | 2 | 3 | No | 2 | 0.43701223 | |
| Sisu - Emboldened Warrior | 3 | 1 | 4 | Yes | 2 | 0.43701223 | |
| Diablo - Devoted Herald | 3 | 2 | 2 | No | 1 | Evasive, | 0.43221931 |
| Lilo - Escape Artist | 2 | 1 | 2 | No | 2 | 0.39137023 | |
| Lefou - Bumbler | 2 | 1 | 2 | Yes | 2 | 0.39137023 | |
| Flynn Rider - Charming Rogue | 2 | 1 | 2 | Yes | 2 | 0.39137023 | |
| Kida - Protector of Atlantis | 5 | 3 | 5 | Yes | 2 | Shift 3, | 0.36749256 |
| Beast - Tragic Hero | 5 | 3 | 5 | Yes | 2 | Shift 3, | 0.36749256 |
| Belle - Accomplished Mystic | 5 | 4 | 4 | Yes | 2 | Shift 3, | 0.36749256 |
| Cursed Merfolk - Ursula's Handiwork | 1 | 0 | 1 | No | 2 | 0.34572822 | |
| Ursula - Sea Witch Queen | 7 | 4 | 7 | Yes | 3 | Shift 5, | 0.31388756 |
| Elsa - The Fifth Spirit | 5 | 2 | 5 | Yes | 1 | Evasive, Rush, | 0.15990734 |
| Cogsworth - Grandfather Clock | 5 | 2 | 5 | Yes | 2 | Shift 3, Ward, | 0.12857222 |
| Chernabog's Followers - Creatures of Evil | 1 | 2 | 1 | Yes | 1 | 0.01343824 | |
| Clarabelle - Clumsy Guest | 1 | 1 | 2 | Yes | 1 | 0.01343824 | |
| Happy - Lively Knight | 1 | 2 | 1 | Yes | 1 | 0.01343824 | |
| Magic Broom - Illuminary Keeper | 1 | 1 | 2 | Yes | 1 | 0.01343824 | |
| Diablo - Maleficent's Spy | 1 | 1 | 2 | Yes | 1 | 0.01343824 | |
| Robin Hood - Champion of Sherwood | 5 | 3 | 6 | Yes | 2 | Shift 3, | -0.10968644 |
| Genie - Wish Fulfilled | 4 | 2 | 4 | No | 2 | Evasive, | -0.14420669 |
| Maui - Half-Shark | 6 | 7 | 5 | No | 1 | Evasive, | -0.38521266 |
| Madam Mim - Snake | 2 | 3 | 3 | Yes | 1 | -0.41809875 | |
| Rafiki - Mystical Fighter | 1 | 0 | 2 | Yes | 1 | Challenger 3, | -0.45560686 |
| Calhoun - Marine Sergeant | 2 | 3 | 2 | No | 1 | Resist 1, | -0.49214103 |
| Go Go Tomago - Darting Dynamo | 2 | 2 | 2 | No | 1 | Evasive, | -0.56778069 |
| Madam Mim - Fox | 3 | 4 | 3 | Yes | 1 | Rush, | -0.73605273 |
| Mr. Smee - Bumbling Mate | 2 | 3 | 3 | Yes | 2 | -1.04016676 | |
| Daisy Duck - Donald's Date | 1 | 1 | 4 | No | 2 | -1.56298777 |
Kruskal-Wallis rank sum test
data: Meta Bespoke Costs, Non-Meta Bespoke Costs
Kruskal-Wallis chi-squared = 2.2244, df = 1, p-value = 0.1358
Meta Bespoke Cost Mean: 0.695605
Non-Meta Bespoke Cost Mean: 0.814527
This is not significant. Remember that this means something different from analyzing the residuals. This tells us that we don't know for sure whether the costs of the bespoke abilities used for meta decks are different from the costs of the bespoke abilities not used for meta decks.
| Is Meta? | Non-Inkable | Inkable |
|---|---|---|
| Yes | 28 | 50 |
| No | 220 | 320 |
Fisher's Exact Test for Count Data
data: Bespoke contingency table
p-value = 0.4595
alternative hypothesis: true odds ratio is not equal to 1
95 percent confidence interval:
0.4780225 1.3662306
sample estimates:
odds ratio
0.8148121
Inconclusive. We really can't say anything at all here.
Miscellaneous analysis#
And now for a couple of quick tests that were easy to do but don't really fit in elsewhere.
Vanilla curves for different ink types#
This would make sense as a possibility. It would be possible for certain Ink colors to have weaker or stronger basic character cards on average, in exchange for having stronger or weaker other cards, or more cards with keyword abilities, or something like that.
| Ink Color | Mean Residual for Basic Cards |
|---|---|
| Steel | -0.124075752 |
| Amber | -0.045788255 |
| Sapphire | -0.002106329 |
| Ruby | 0.057681882 |
| Emerald | 0.060559613 |
| Amethyst | 0.061776093 |
Kruskal-Wallis rank sum test
data: Residuals by Ink Color for Basic Card
Kruskal-Wallis chi-squared = 3.5087, df = 5, p-value = 0.6221
It looked at first like Steel cards might've been slightly more powerful, but there is no significant effect.
Rarities and Residuals#
Rarer cards are not necessarily better value for their Ink cost.
| Rarity | Mean Residual for Basic Cards |
|---|---|
| Common | -0.01069499 |
| Uncommon | 0.11113186 |
| Rare | -0.17159699 |
Kruskal-Wallis rank sum test
data: Residuals by Rarity for Basic Cards
Kruskal-Wallis chi-squared = 2.4492, df = 2, p-value = 0.2939
| Rarity | Mean Residual for Kwonly Cards |
|---|---|
| Common | -0.01254122 |
| Uncommon | 0.11939541 |
| Rare | -0.07916795 |
| Super Rare | -0.18535224 |
| Legendary | 0.70294129 |
Kruskal-Wallis rank sum test
data: Residuals by Rarity for Kwonly Cards
Kruskal-Wallis chi-squared = 5.1727, df = 4, p-value = 0.27
Rarities and Complexity#
Rarer cards are more complex.
| Card Type | Common | Uncommon | Rare | Super Rare | Legendary |
|---|---|---|---|---|---|
| Basic | 92 | 49 | 26 | 0 | 0 |
| Kwonly | 77 | 20 | 6 | 3 | 1 |
| Bespoke | 153 | 148 | 149 | 99 | 69 |
The one kwonly legendary card is "Mickey Mouse - Brave Little Tailor", which was one of the first Lorcana cards revealed. I suspect that we won't get another kwonly legendary.
Fisher's Exact Test for Count Data with simulated p-value (based on 1e+05 replicates)
data: Rarity contingency table
p-value = 1e-05
alternative hypothesis: two.sided
Is there power creep yet?#
For this, we train a linear model on the residuals of the basic and kwonly models, with set number as the independent variable. The question is whether the slope parameter is significantly non-zero.
Model:
Residual = 0.08011 - 0.02354 * Set_Num
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.08011 0.04956 1.616 0.1072
Set_Num -0.02354 0.01350 -1.744 0.0823 .
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.3887 on 272 degrees of freedom
Multiple R-squared: 0.01106, Adjusted R-squared: 0.007423
F-statistic: 3.042 on 1 and 272 DF, p-value: 0.08229
The slope parameter is not significantly non-zero, and it is even a little negative, so we can conclude that Lorcana has so far avoided power creep for basic and kwonly cards.
Of course, it could be the case that there is power creep but only in the bespoke cards. It is also true that competitive decks will tend to get more powerful over time even if the population characteristics of the cards remain the same, because competitive players will take the best cards from the total population.
Discussion#
With the main work of modeling and validating out of the way, I want to share some observations about Lorcana that have been informed by this exercise.
Why is Reckless priced as a buff?#
Reckless only makes sense if the card is assumed to have one lore for Cost reasons. If it doesn't, then Reckless is priced as a buff despite being a debuff. Only one Reckless card is meta-relevant, and that is because it is the best card for what it does for Ruby. Otherwise all the Reckless cards are bad, because you're paying for a lore that you never get to use.
Reckless does have synergy with "Who's with me?", but that is not the reason for balancing Reckless the way it is, because "Who's with me?" is a relatively recent Set 5 card and is not meta-relevant. Many other abilities inflect Reckless on opposing cards as a debuff.
I would be curious to hear what the designers think of Reckless. It's very possible that I'm missing something that explains why Reckless cards are valued the way that they are.
What is Inkability for?#
Inkability doesn't seem to matter to the Ink price of basic and kwonly cards. Inkability doesn't seem to matter to the popularity of a card in the meta. What is it for?
It is well-understood that you need to restrict the number of non-Inkables in your deck. If you have too many non-Inkables, then your deck becomes inconsistent because you will sometimes be unable to ramp up your inkwell. The article from a high-level player that I linked earlier has a good explanation of the math.
So the purpose of Inkability is to restrict deck construction by dividing cards into two classes and limiting the number of the second class that you can include in your deck.
Evaluating a card's desirability within a deck is a completely different thing from evaluating it individually. It seems like the designers decided to mostly not use Inkability as an input to the Ink cost of a card, even though they could have.
Because all of my modeling is towards evaluating individual cards, and not constructing decks, it will not tell me why certain cards are in the Inkable set and the non-Inkable set, so I can only speculate.
Maybe Inkability is used as a counter to keep cards from being too popular? They design cards, playtest with them, and make any card that everyone consistently picks non-Inkable in order to keep it from showing up in everyone's decks?
If that's the case, then it's probably a useful property for the proportion of bespoke cards that are inkable in metadecks to match the proportion of bespoke cards that are inkable overall, and that would explain why Inkability doesn't seem to matter for popularity of a card in the meta. It would be a signal that the designers are doing a good job at predicting which cards will be popular.
Maybe Inkability is a tool to limit the number of combos that you can pack into a deck? If you have a pair of cards that go together, like a Flotsam and Jetsam or a Chip and a Dale, then making one or both of them non-Inkable limits the number of such pairs that you can put into a deck.
Both of the preceding possibilities would be ways to increase deck diversity. If a new Inkable card comes out that is very good, then every deck may end up including it from now on. If a new non-Inkable card comes out, then it may have a shorter half-life in competitive play. So then the designers could try out new concepts with non-Inkables, and if they are fun and players like them, then they could be reprinted as Inkables. If they end up being too powerful, or not fun, then having them be non-Inkable limits the damage. If they are fun and players like them but they aren't popular competitively, then they could be reprinted as Inkables to give them another chance to catch on.
Maybe Inkability does have a clear cost, but only for bespoke abilities, and having non-Inkable basic and kwonly cards is an afterthought. I consider this unlikely, but I mention it because it is another possibility that is consistent with the data that I have.
When are single-card models useful?#
Our models for predicting the ink costs of individual cards may be good for a few situations:
- Homebrewing new cards that are not re-skins of existing cards. Having a model gives you a good idea of where the gaps that you can explore are, and helps you pre-balance your new cards before playtesting with them.
- Having a simple heuristic for picking good cards in isolation for a drafting game.
- As a starting point for deck building.
It is pointedly not good for evaluating a deck for competitive play, because it does not take into account interactions between different cards, or ways that certain cards can be countered. My models will only tell you a value for individual (basic or kwonly) cards in isolation, or individual bespoke abilities in isolation. It won't tell you anything about combinations of cards.
I do think that the information could be helpful for building decks, but only as a starting point. Picking good individual cards is a small part of the total process of figuring out a competitive deck.
The way that I think it adds value to deck-building is to help you understand whether you are getting good value for adding a card into your deck. If the game tells you that a bespoke ability is worth a certain amount of Ink, but you figure out a way to use the card that is worth more to you than that amount of Ink, then it is probably good value to include that card in your deck.
I think that you could probably put together some interesting and unique decks by thinking up a bunch of card combinations, evaluating them against the model to figure out which ones give you the most extra Ink value over their costs, and then just picking the best ones. I doubt this would be enough to win tournaments but it could take a beginner pretty far.
Future Work#
I don't plan to do any more work on this, but my code and data are available to anyone who does want to.
I did very little detailed analysis of the bespoke abilities, even though there is a lot of structure within them. It would have been too much manual work. I tried to automate some of this with AI tools, but I was unable to get it to work well. Others may have more luck.
It's very easy to pose questions and very time-consuming to answer them rigorously. So I've laid a foundation, and here's all the things that I thought about but won't investigate:
Many abilities decompose into a set of effects that happen under certain situations. Many abilities are repeated under different names. Many abilities are just conditional keywords. How do we break abilities into factors in a way to lets us model their value accurately?
What is the discount factor for certain conditions? How much of a discount do you get for being evasive only on your turn? How much of a premium do you pay for giving a keyword to a chosen character each turn vs having it for yourself?
Many when-played abilities are also available standalone as action cards, and those action cards have a true ink cost, so that could be compared against the estimated cost of the bespoke ability based on the character. Similarly, many exert-to-activate abilities are also available standalone as item cards.
You could imagine that an action/item would be cheaper when bundled with a character, as a reward for pulling off complex combos. You could also imagine that it would be more expensive because it saves space in your deck. Which is it? I don't know.
What's the exchange rate between lore and ink? "Gathering Knowledge and Wisdom" implies that it's 1-to-1, but is that generally true? What about lore-removal and ink? At a 1-to-1 ratio for gaining lore, "Thievery" gives you one lore-removal for free. Is lore-removal undervalued in two-player games in order to make up for it being overvalued in many-player games?
Is lore from locations worth the same ink cost as lore from characters? A location can be thought of as a character card with no strength that always quests, so that is at least plausible.
A song card is an action card with a slight cost premium because there are two ways to pay for it. Do song cards actually have a cost premium over equivalent actions?
I completely ignored Classifications (storyborn/dreamborn/floodborn, hero/ally/princess/pirate/alien/etc.). Do some of them matter?
It's possible to model the keywords in greater detail than I did here. Should there be interaction terms between Strength/Willpower/Lore and some of the keywords? Should there be a term for Strength minus Willpower in order to take into account how unbalanced cards can be more useful than balanced cards in some situations? Is Lore on a high-Willpower card worth more because you can quest for it more times on average?
Inkability is a global property, in the sense that it doesn't seem to affect the cost of individual cards much but you need to keep a certain number in your deck. It's also an entirely different way to play a card, so it definitely doesn't interact with anything and should be a flat cost. But what is that cost, and why couldn't I find it conclusively?
I mentioned gaps in the game and homebrew cards. What if you go really crazy? Give characters five different keywords and pay for them with higher ink or less strength/willpower/lore. That could be fun. Or combinations of keywords that don't exist in the game yet. Or pull items and actions out of characters, or push them in. What happens if you push the limits of Shift and Singer to allow powerful cards to be played earlier in the game? What about adding zero Ink cost cards whose predicted cost is < 0.5 ink? Could we flip some of the most positive bespoke abilities into negative ones that affect the active player? These models give you guidance on how to quickly build a very wacky game in a way that might not be that unbalanced.
It really seems like there's a deep structure here that can be expanded much farther then I've done. I would love for someone to build on what I've done and answer some of these questions.
Once more, here are the links. Go wild.
Thank you to Ansh Sancheti for providing feedback on drafts of this post. All mistakes are my own.